Url Shortner in Golang
I am curious kid on the web, trying to learn more about life and other things. I enjoy building things and my medium of expression is mostly code. I have been dabbling with OpenEdx recently. I love to talk about distributed system, I have taken up learning Rust recently and been writing Python, Golang and JavaScript for a while.
TLDR; Trying to learn new things I tried writing a URL shortner called shorty. This is a first draft and I am trying to approach it from first principle basis. Trying to break down everything to the simplest component.
I decided to write my own URL shortner and the reason for doing that was to dive a little more into golang and to learn more about systems. I have planned to not only document my learning but also find and point our different ways in which this application can be made scalable, resilient and robust.
A high level idea is to write a server which takes the big url and return me a short url for the same. I have one more requirement where I do want to provide a slug i.e a custom short url path for the same. So for some links like https://play.google.com/store/apps/details?id=me.farhaan.bubblefeed, I want to have a url like url.farhaan.me/linktray which is easy to remember and distribute.
The way I am thinking to implement this is by having two components, I want a CLI interface which talks to my Server. I don’t want a fancy UI for now because I want it to be exclusively be used through terminal. A Client-Server architecture, where my CLI client sends a request to the server with a URL and an optional slug. If a slug is present URL will have that slug in it and if it doesn’t it generates a random string and make the URL small. If you see from a higher level it’s not just a URL shortner but also a URL tagger.
The way a simple url shortner works:
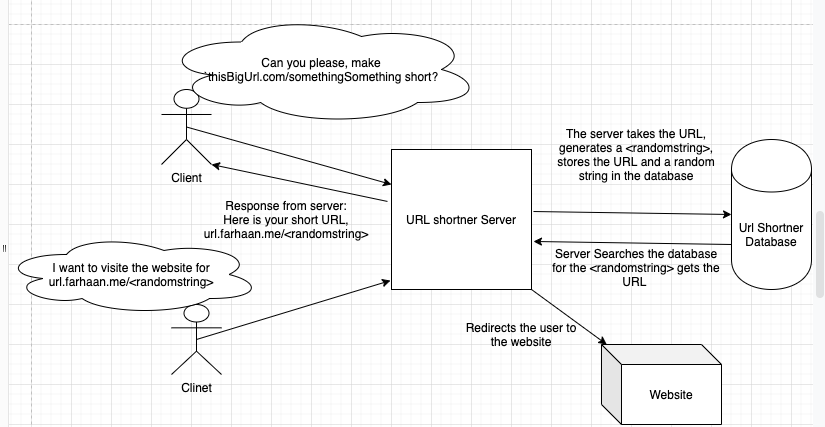
Flow Diagram
A client makes a request to make a given URL short, server takes the URL and stores it to the database, server then generates a random string and maps the URL to the string and returns a URL like url.farhaan.me/.
Now when a client requests to url.farhaan.me/, it goest to the same server, it searches the original URL and redirects the request to a different website.
The slug implementation part is very straightforward, where given a word, I might have to search the database and if it is already present we raise an error but if it isn’t we add it in the database and return back the URL.
One optimization, since it’s just me who is going to use this, I can optimize my database to see if the long URL already exists and if it does then no need to create a new entry. But this should only happen in case of random string and not in case of slugs. Also this is a trade off between reducing the redundancy and latency of a request.
But when it comes to generating a random string, things get a tiny bit complicated. This generation of random strings, decides how many URLs you can store. There are various hashing algorithms that I can use to generate a string I can use md5, base10 or base64. I also need to make sure that it gives a unique hash and not repeated ones.
Unique hash can be maintained using a counter, the count either can be supplied from a different service which can help us to scale the system better or it can be internally generated, I have used database record number for the same.
If you look at this on a system design front. We are using the same Server to take the request and generate the URL and to redirect the request. This can be separated into two services where one service is required to generate the URL and the other just to redirect the URL. This way we increase the availability of the system. If one of the service goes down the other will still function.
The next step is to write and integrate a CLI system to talk to the server and fetch the URL. A client that can be used for an end user. I am also planning to integrate a caching mechanism in this but not something out of the shelf rather write a simple caching system with some cache eviction policy and use it.
Till then I will be waiting for the feedback. Happy Hacking.
I now have a Patreon open so that you folks can support me to do this stuff for longer time and sustain myself too. So feel free to subscribe to me and help me keeping doing this with added benefits.